Microsoft a enrichi son offre de traitement des données volumineuses Azure Data Lake présenté à la conférence Build en avril dernier avec des outils d’analyse et de traitement des données » plus simples et plus accessibles « ainsi que l’explique sur le blog de l’éditeur le vice-président Data Platform de Microsoft, TK “Ranga” Rengarajan.
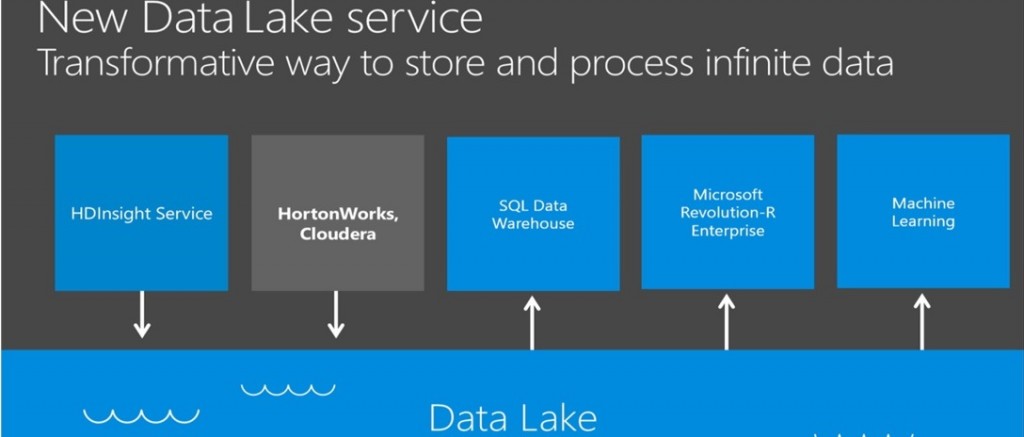
Cette évolution passe par un changement de nom : Azure Data Lake devient Azure Data Lake Store, désormais un simple lieu de stockage d’où pourront être extraites et partagées des données de tous types et formats sans rien changer aux applications qui les traitent. Ces big data seront notamment accessibles aux outils et applications utilisant le système de fichier HFDS Hadoop. Azure Data Lake Store sera disponible en preview avant la fin de l’année.
Un nouveau service Azure Data Lake Analytics basé sur Apache Yarn sera également disponible en bêta cette année. Il utilise le langage de requête U-SQL qui permet d’associer son propre code avec SQL afin d’analyser les données directement dans Azure Data Lake Store, ou via SQL Server dans Azure, Azure SQL Database et Azure SQL Data Warehouse.
Le service de clusters Hadoop Azure HDInsight est désormais inclus dans Azure Data Lake Store permettant d’analyser les données avec des moteurs open source tels que Hive, Spark, HBase et Storm.
TK “Ranga” Rengarajan annonce par ailleurs des clusters gérés sous Linux avec une disponibilité annoncée de 99,99%.
Est également prévu, Azure Data Lake Tools for Visual Studio un outil permettant de déboguer des tâches U-SQL depuis la suite de développement.
Microsoft ne fournit aucune indication sur les tarifs qui seront appliqués.